


We were asked to write a blog post about how we integrated a static type checker into our Python codebase and thought of Alice Neel.
It is a bit of a reach. Alice Neel was one of the greatest portrait painters ever and a master of Expressionism. Static type checkers are about as expressionist as a can of sardines and, by all accounts, have not yet been featured in The Met.
Here’s one of Alice’s paintings:

It depicts James Hunter, a Vietnam War draftee who disappeared the day after the painting was begun. Alice signed the picture, considering it complete.
Flash forward 58 years and a fast-growing SaaS procurement company named Zip is developing a product that has nothing to do with Alice Neel or James Hunter. In the spirit of fast and flexible product iteration, the supporting codebase is largely written in untyped Python. Here’s what that looks like:
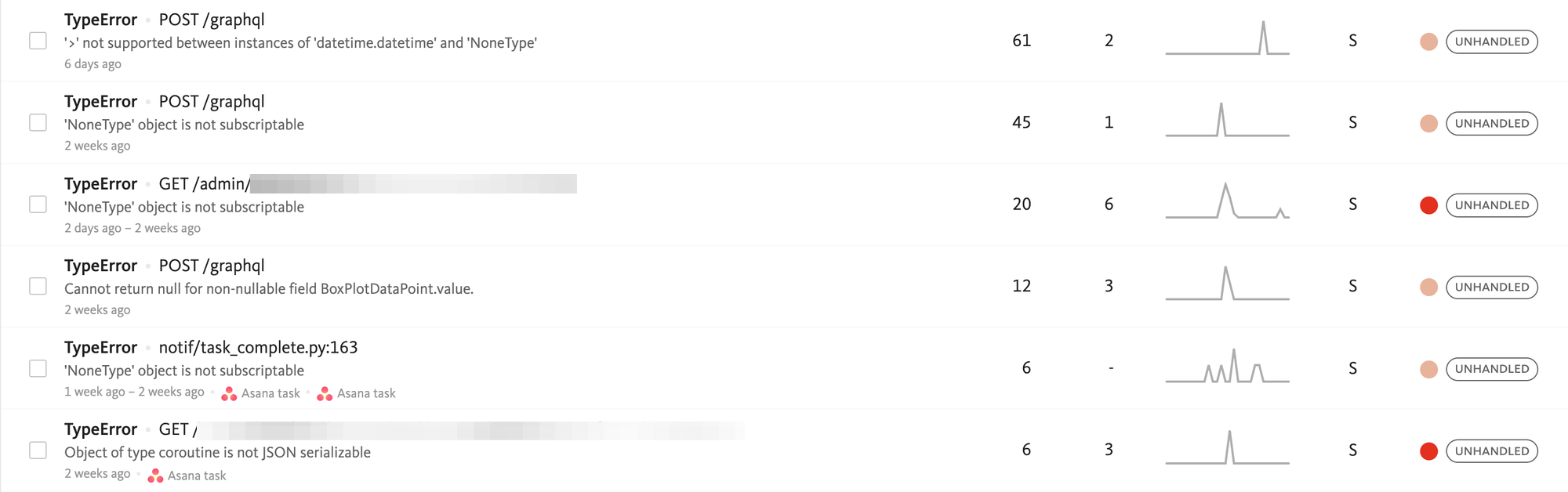
Yikes.
Most untyped codebases inevitably suffer the same fate. An accessor method may produce a nullable value; a caller might forget to handle said nullable value; a caller of that caller (a grandcaller) might also forget. Once a codebase has accumulated years of layered changes, not even 100% test coverage will help.
The best way to capture type errors is static type checking. With the right IDE, type checking provides immediate feedback and actionable documentation. It prevents code from being misused, which is critical for a shared repository with frequent contributions, and does so with the lowest level of effort.
Great. All we have to do is pick a type checker and implement it. Should be easy, right?
Picking a Static Type Checker
Python is one of the most popular programming languages (if not the most popular), so there are several options for static type checking. We kicked off the hunt toward the end of 2022 and evaluated Pyre, Pytype, Pyright, and Mypy based on the following criteria:
- Performance (important) - our codebase spanned over 6,000 files.
- Number and quality of errors captured (very important) - we knew we would start with many annotations missing, so we needed a type checker able to report errors based largely on type inference.
- Type inference - see above. Ideally, we wanted a type checker able to report inferred types so we could merge them back into the codebase.
- VSCode support.
We tabulated the following results:
| Performance | Errors surfaced | Inference | VSCode support | |
|---|---|---|---|---|
| Pyright | Good | Good | Good | Very good |
| Pyre | Good | Bad | Good | Good |
| Pytype | Very bad | Good | Good | Bad |
| Mypy | Bad | Very bad | Very bad | Good |
This analysis is reductive and dated in 2024. Mypy allows builds to be incrementally generated from a cache and their type inference has improved over the past two years, so they look a little better than when we ran our comparison. We still think Pyright is the best tool for the job, though. It has the following advantages:
- VSCode support: VSCode is the most popular IDE by far (according to the StackOverflow Developer Survey). This is true especially at Zip, where VSCode is widely used with our frontend TypeScript codebase.
- Performance: Pyright was the fastest type checker among the options we evaluated. It took less than three minutes to analyze our entire codebase from a clean start. After more than doubling the size of our codebase, it continues to run in under four minutes.
- Popularity and active development: Pyright releases almost every week. At the time of writing it is downloaded over two million times each month. Pyright is backed by Microsoft indirectly via their Pylance product. Pyright’s author, Eric Traut, is a regular contributor to the Python typing system and has added essential features to the language (e.g., PEP 695).
- Thoroughness: In our evaluation, Pyright caught more errors than Pyre and many more than Mypy. Pyright is exceptionally good at type narrowing and inference, which is particularly important if adding a type checker to an unannotated codebase.
Act I: The Migration Begins
We decided to move forward with Pyright and immediate integration of new code. This meant getting it in the hands of developers as fast as possible and adding it to our continuous integration environment.
Our Pyright MVP consisted of four objectives:
- A developer guide with local setup instructions and references for Python typing conventions / common errors and resolutions.
- Running Pyright on all changed files in our local pre-commit hook.
- Running Pyright via Github Actions as a required check, blocking PRs on new errors.
- Grandfathering all existing code to reduce the friction of adoption.
We built a LibCST codemod to add a # type: ignore comment to the top of every existing Python file:
from __future__ import annotations
import argparse
from typing import Sequence
import libcst
from libcst.codemod._visitor import ContextAwareTransformer
class AddTypeIgnoreComment(ContextAwareTransformer):
COMMENT_VALUE = "# type: ignore"
DESCRIPTION = "Adds a `# type: ignore` comment to the module header."
@staticmethod
def add_args(_: argparse.ArgumentParser) -> None:
pass
def _get_header_with_comment(
self,
node: libcst.Module,
) -> Sequence[libcst.EmptyLine]:
for header in node.header:
if header.comment and header.comment.value == self.COMMENT_VALUE:
return node.header
if node.header and not node.header[-1].comment:
header = node.header[:-1]
else:
header = node.header
return [
*header,
libcst.EmptyLine(comment=libcst.Comment(self.COMMENT_VALUE)),
libcst.EmptyLine(),
]
def leave_Module(
self, original_node: libcst.Module, updated_node: libcst.Module
) -> libcst.Module:
return updated_node.with_changes(
header=(*self._get_header_with_comment(original_node),)
)
The # type: ignore comment strategy was done to encourage writing new files with complete annotations and no type errors without imposing an undue burden on developers working with legacy files. Also, comments are generally easier to deal with than a blocklist containing 6,000 files.
Within two weeks, Pyright was integrated into our monorepo:

Limitations of the Original Implementation
We got our foot in the door with the MVP, but were pretty far from our original type checking vision. We wanted to run Pyright on every line of code, but the reality was that most files continued to be ignored, particularly the files that need it the most: Large and unwieldy legacy files representing years of accumulated business logic, often with limited test coverage. These files continued to receive regular updates without any kind of enforced type checking. To make things worse, many new files imported code from these legacy files and inherited any associated type errors. Legacy files produced a very poor reference for many developers who often cargo-culted the # type: ignore comment from the header.
Eventually, we realized that we needed to move away from file-level ignores. In early 2023, we formed a new working group to tackle the problem. Ultimately, we decided to migrate to line-level ignores, which offer significantly improved granularity at the cost of clutter and a more expensive migration.
Act 2: Encouraging Adoption
One of the striking aspects of Alice’s work is the blend of objectivist and impressionist elements. Yes, her paintings are abstract representations of real people. And yet, they might just be the truest form of their subjects - telling you everything you need to know in a glance.
To carry the rather belabored metaphor a bit further, line-level ignores will show you exactly how healthy your codebase is. You’ll see every error made evident, loudly alerting you to some unpleasant inconsistency (or calmly, depending on your editor’s color scheme). Too many errors can be overwhelming.
We’ve been through at least one large typing migration (several millions of lines) that ultimately started with a coverage percentage in the mid-80s (coverage defined again as the percentage of lines without ignores). That should be the minimum threshold. After all, consider what 85% coverage looks like visually:
def my_wonderful_method(my_lovely_arg: dict[str, tuple[int|str, ...]]) -> str:
total: int = 0
for key, value in my_lovely_arg.items():
if key == "a":
print("Unbelievable. How did this get here?")
continue
for item in value:
if isinstance(item, str):
total += item # pyright: ignore[reportGeneralTypeIssues,reportUnknownVariableType]
elif isinstance(item, int): # pyright: ignore[reportUnnecessaryIsInstance]
total += len(item) # pyright: ignore[reportGeneralTypeIssues,reportUnknownVariableType]
remainder = cast(int, total % 2)
if remainder == 0:
return "Even"
else:
return "Odd"
At 90%, one out of every 10 lines has an ignore. At 95%, one out of 20. At 80% you will read four lines and then ignore the fifth like Harvey Keitel in Bad Lieutenant.
“I didn’t come here for simple math,” you might be thinking. “Can you give me real technical detail?” Certainly.
The Hierarchy of Typing Trust
A simple way to add typing annotations to your code is to fold in your type checker’s inferred types. Although this doesn’t necessarily improve coverage, it has several advantages: First, it gives developers something to work off of; then, future additions will have to respect the existing types. Also, if your type checker inferred these types, they must be trustworthy (in that they won’t cause new unexpected errors).
Pyright, specifically, has a --createstub flag that can be used to generate type stubs. Run it on your repo root and it will save the generated stubs to ./typings, or wherever you’ve set your stubPath.
Once you have the stubs, you need to merge them back into the codebase. Pytype uses a LibCST codemod to accomplish this - ours is similar.
class AddPyrightInferredTypes(VisitorBasedCodemodCommand):
DESCRIPTION = """
Merges Pyright-inferred .pyi stubs into the original .py files.
Command: ```
python -m libcst.tool codemod add_pyright_inferred_types.AddPyrightInferredTypes <path/to/file.py>
```
"""
TYPE_COMMENT_REGEX = r"\\): # -> (.+):"
def get_annotation(
self,
match: re.Match[str],
has_annotations: dict[str, bool],
) -> str:
if "Unknown" in match.group(1):
has_annotations["any"] = True
annotation = match.group(1).replace("Unknown", "Any").replace(" ", "")
return f") -> {annotation}:"
def leave_Module(self, original_node: Module, updated_node: Module) -> Module:
filename = self.context.filename
if not filename:
return updated_node
pyi_filename = filename.replace("/src/", "/src/typings/").replace(".py", ".pyi")
if not os.path.isfile(pyi_filename):
return updated_node
context = CodemodContext()
has_annotations: dict[str, bool] = {
"any": False,
}
pyi_file = re.sub(
self.TYPE_COMMENT_REGEX,
lambda match: self.get_annotation(match, has_annotations=has_annotations),
open(pyi_filename, encoding="UTF-8").read(),
)
pyi_module = parse_module(pyi_file)
if has_annotations["any"]:
AddImportsVisitor.add_needed_import(context, "typing", "Any")
ApplyTypeAnnotationsVisitor.store_stub_in_context(
context=context,
stub=pyi_module,
)
return ApplyTypeAnnotationsVisitor(context).transform_module(updated_node)
There are two complications here: Adding the imports from typing and correcting Pyright’s type comment syntax. Otherwise, the transformation was relatively straightforward, excepting the inference of some deeply-nested unions that alerted us to cyclomatic complexity in our code.
Next, we have the second-most trustworthy method of adding annotations: Heuristics. autotyping has an excellent set of stable heuristics that we used to annotate our code. Give the --safe changes a shot and annotate some common shared arguments (in our case, the GraphQL resolver info argument, which represents a singleton).
If you still haven’t reached a satisfying level of coverage, you might consider using MonkeyType to collect types at runtime (and subsequently generate stubs that you can then merge back into your code with LibCST’s ApplyTypeAnnotationsVisitor). We ran MonkeyType on our test suite locally - you could also collect types from successful CI builds on the main branch. Unfortunately MonkeyType did not significantly expand our coverage and generated types that diverged from our canonical types (e.g., str in place of ObjectUUID), but maybe you’ll have better luck.
After all that fuss, we ended up with around ~85% coverage. There must be something magical about that number that many of the migrations we’ve been a part of or heard about end up there initially.
Leaving Errors on Read
At 85% coverage, three out of 20 lines have a typing error. You now need to ignore these errors by placing a comment on the associated lines.
Doesn’t sound too bad, right? Run Pyright, get all the lines that have errors, and then insert a comment at the end of the line.

Unfortunately, formatters exist, and they love breaking up lines (like the Taft–Hartley Act). Take this line, for example:
if isinstance(result, ExecutionResult | ExperimentalIncrementalExecutionResults): # pyright: ignore[reportUnknownVariableType]
It’s so long we wager you had to scroll over to see the comment. Here’s how Black treats it:
if isinstance(
result, ExecutionResult | ExperimentalIncrementalExecutionResults
): # pyright: ignore[reportUnknownVariableType]
Unfortunately, we are no longer ignoring the right line.
Note: Ruff has implemented a fix for this problem that bypasses many of the difficulties we faced in our migration. We suggest using it over Black.
We came up with two different options for solving the problem. The first was to use the positioning metadata of Pyright’s reported errors (specifically, line and column positioning) to insert comments where appropriate. That is, given an error like:
/repos/.../application_config.py:219:17 - error: Type annotation not supported for this statement (reportGeneralTypeIssues)
We would attempt to add a comment to the matching LibCST node on line 219 and column 17, or any node spanning a range of lines or columns inclusive of this position.
Unfortunately, that solution fell apart pretty quickly. Not all nodes support comments. Nodes spanning multiple lines might need the comment inserted on the first line, not necessarily the line matching the reported error. The code became a complex mess almost immediately.
So, if precision won’t work, then what will?
As it turns out, Pyright supports a rule named reportUnnecessaryTypeIgnoreComment that will flag unnecessary # type: ignore comments as errors. If we instead write a codemod to insert a # type: ignore comment into every possible node, we can run another codemod to remove the unnecessary comments. By “every possible node” we mean nodes that are likely to terminate a line, meaning:
LeftParenParenthesizedWhitespaceLeftSquareBracketTrailingWhitespace- etc.
A block of code that looks like this:
def visit_ParenthesizedWhitespace(self, node: ParenthesizedWhitespace) -> bool | None:
self._set_pyright_errors_by_node(node=node)
return True
Ends up looking something like this:
def visit_ParenthesizedWhitespace( # pyright: ignore
self, # pyright: ignore
node: ParenthesizedWhitespace, # pyright: ignore
) -> None: # pyright: ignore
self._set_pyright_errors_by_node( # pyright: ignore
node=node # pyright: ignore
)
return True # pyright: ignore
After the removal of the unnecessary comments, you’d end up with this:
def visit_ParenthesizedWhitespace(
self,
node: ParenthesizedWhitespace,
) -> None:
self._set_pyright_errors_by_node(node=node)
return True # pyright: ignore
Of course, this comes with its own complications. The codemod may need to run multiple times to correctly ignore all the errors that would otherwise collapse into one unignored line (at the time we wrote the codemod, Black had some issues with # pyright: ignore comments and would routinely move them to other lines. Again, Ruff solves the problem quite nicely).
And now, we remove the unnecessary comments:
from __future__ import annotations
import os
import re
import subprocess
import sys
from dataclasses import dataclass
from typing import cast
from libcst import Comment, Module, RemovalSentinel
from libcst.codemod import CodemodContext, VisitorBasedCodemodCommand
from libcst.metadata import PositionProvider
@dataclass(frozen=True, slots=True)
class PyrightError:
rule: str
class RemoveUnnecessaryPyrightIgnoreComments(VisitorBasedCodemodCommand):
DESCRIPTION = """
Removes unnecessary `pyright: ignore` comments.
Command: ```
python -m libcst.tool codemod --jobs=1 remove_unnecessary_pyright_ignore_comments.RemoveUnnecessaryPyrightIgnoreComments <path/to/file.py>
```
"""
COMMENT_REGEX = r"(?:pyright|type): ignore(?:\\[(.+)\\])?"
COMMENT_RULE_REGEX = r"pyright: ignore\\[([a-zA-Z,]+)\\]"
COMMENT_VALUE = "pyright: ignore"
METADATA_DEPENDENCIES = (PositionProvider,)
# {filename}:{line}:{column} - error: Unnecessary " " rule: "{rule}"
PYRIGHT_ERROR_REGEX = (
r'(.+):(\\d+):(\\d+) - error: Unnecessary "# pyright: ignore" rule: "(\\w+)"'
)
pyright_errors_by_comment: dict[Comment, list[PyrightError]] = {}
pyright_errors_by_line: dict[int, list[PyrightError]] = {}
pyright_errors_by_line_by_filename: dict[str, dict[int, list[PyrightError]]] = {}
def __init__(self, context: CodemodContext) -> None:
super().__init__(context)
filenames = [self.context.filename] if self.context.filename else sys.argv[3:]
pyright_project = cast(str | None, self.context.scratch.get("pyright_project"))
pyright_args = (
[
"pyright",
"-p",
pyright_project,
*filenames,
]
if pyright_project
else ["pyright", *filenames]
)
pyright_stdout = (
os.getenv("PYRIGHT_OUTPUT")
or subprocess.run(
pyright_args,
capture_output=True,
check=False,
env=dict(os.environ, NODE_OPTIONS="--max-old-space-size=8192"),
text=True,
).stdout
)
self._set_pyright_errors_by_line_by_filename(pyright_stdout)
def _set_pyright_errors_by_line_by_filename(self, pyright_stdout: str) -> None:
for filename, line, *_, rule in re.findall(
self.PYRIGHT_ERROR_REGEX, pyright_stdout
):
self.pyright_errors_by_line_by_filename.setdefault(
filename.strip(), {}
).setdefault(int(line), []).append(PyrightError(rule=rule))
def visit_Module(self, node: Module) -> bool | None:
pyright_stdout = os.getenv("PYRIGHT_OUTPUT")
if pyright_stdout:
self._set_pyright_errors_by_line_by_filename(pyright_stdout)
self.pyright_errors_by_line = {}
if (
not self.context.filename
or self.context.filename not in self.pyright_errors_by_line_by_filename
):
return False
self.pyright_errors_by_line = self.pyright_errors_by_line_by_filename[
self.context.filename
]
return True
def visit_Comment(self, node: Comment) -> bool | None:
metadata = self.get_metadata(PositionProvider, node)
if metadata.start.line in self.pyright_errors_by_line:
self.pyright_errors_by_comment[node] = self.pyright_errors_by_line[
metadata.start.line
]
return True
def leave_Comment(
self, original_node: Comment, updated_node: Comment
) -> Comment | RemovalSentinel:
if original_node not in self.pyright_errors_by_comment:
return updated_node
comment_rules = {
comment_rule
for _comment_rules in re.findall(
self.COMMENT_RULE_REGEX, original_node and original_node.value or ""
)
for comment_rule in _comment_rules.split(",")
if _comment_rules and comment_rule
}
comment_value: str | None = None
pyright_errors = self.pyright_errors_by_comment[original_node]
rules = comment_rules - {pyright_error.rule for pyright_error in pyright_errors}
if rules:
rules_str = ",".join(sorted(rules))
pyright_ignore_comment_value = f"{self.COMMENT_VALUE}[{rules_str}]"
comment_value = " ".join([
pyright_ignore_comment_value,
re.sub(self.COMMENT_REGEX, "", original_node.value)
.replace("#", "")
.strip(),
]).strip()
return (
Comment(f"# {comment_value}") if comment_value else RemovalSentinel.REMOVE
)
That’s a doozy. The ignore codemod looks even worse, if you can believe it. But it worked! We ended up with a few hundred errors that had to be manually corrected, which is decent for a codebase spanning ~500k lines at the time. We continue to use these codemods to re-ignore our codebase after major changes.
Act 3: The 98th percentile
Like we mentioned previously, 85% coverage simply isn’t good enough. We looked for strategies to quickly improve coverage in the months following the migration.
Some of the projects our group took on that resulted in huge coverage jumps and usability improvements include:
- Typing of core internal libraries: Many of our internal frameworks had poor typing coverage, making them unsafe to work with and cascading type errors to the rest of the codebase. Our data model abstraction, logging frameworks, and search API were particularly noxious hotspots. We spent some time manually adding types to these files (prioritizing the most commonly-called APIs).
- Type stubs for third-party dependencies: Many Python packages are either completely or partially missing annotations and have type stub packages that can be installed separately. We added stubs for graphene, Flask, SQLAlchemy, celery, and boto3 (among others). A list of type stubs for commonly-used packages can be found at typeshed, which comes bundled with Pyright. Others can be found by searching on PyPi.
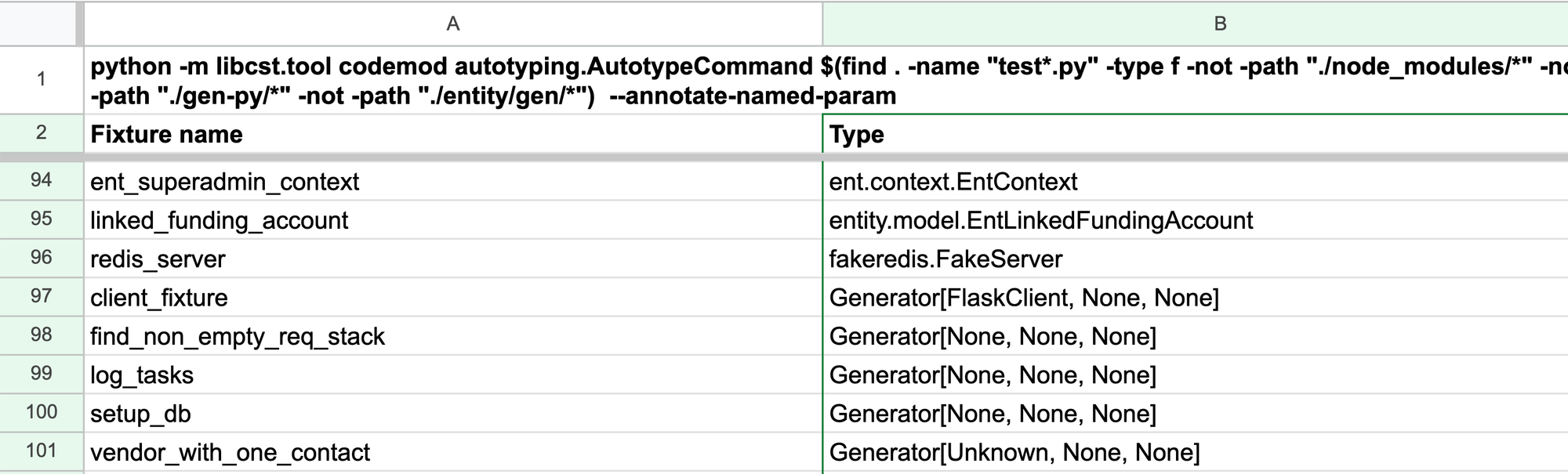
- Test code: Many of our pytest fixtures were untyped, littering tests with
pyright: ignores. Fortunately, we have a limited number of fixtures to annotate. We were able to fix most cases withautotyping, followed by our re-ignore codemod:
- Thrift enums: We use Thrift to share enums between our Python and TypeScript codebases, but the Python ones were generated as vanilla classes instead of
IntEnums, which caused errors like:
# Generated with thrift <0.16
class NotifType(object):
NEW_REQUEST = 1
NEW_APPROVAL_REQUEST = 2
NEW_COMMENT = 3
def create_notification(notif_type: NotifType, ...):
...
# pyright error: "Literal[1]" is incompatible with "NotifType"
create_notification(NotifType.NEW_REQUEST, ...)
After applying a couple patches to the Apache source, released in thrift==0.16, we got Thrift to generate actual enums:
# Generated with thrift >=0.16
class NotifType(**IntEnum**):
NEW_REQUEST = 1
NEW_APPROVAL_REQUEST = 2
NEW_COMMENT = 3
# No more errors!
create_notification(NotifType.NEW_REQUEST, ...)
Seeking assistance
The majority of the remaining ignores were deeply nested inside product code and required manual intervention from code owners. Engineers recognized the value of Pyright in the development process and the resulting reduction of TypeErrors, but maintaining and improving type coverage wasn’t yet a priority for product teams. For most engineers, it was still unpleasantly common to run into files littered with # pyright: ignore[reportUnknownMemberType]s.
We began by adding a GitHub Action that reports the current Pyright coverage and delta from the merge base for positive reinforcement, accompanied by a picture of an astonishingly cute zebra.
We started tracking coverage via Datadog metric and monitored it biweekly, calling out big changes on Slack and in Engineering meetings. We built a leaderboard to track ignores removed by individual contributors, and disbursed awards to top contributors every quarter to build recognition. All of this was part of a larger effort to bring awareness to and tackle tech debt — blog post on that coming soon!
Over time, teams began to prioritize cleaning up ignores across the codebase in their own quality sprints, and today some of the biggest contributions to type coverage come from product team members.
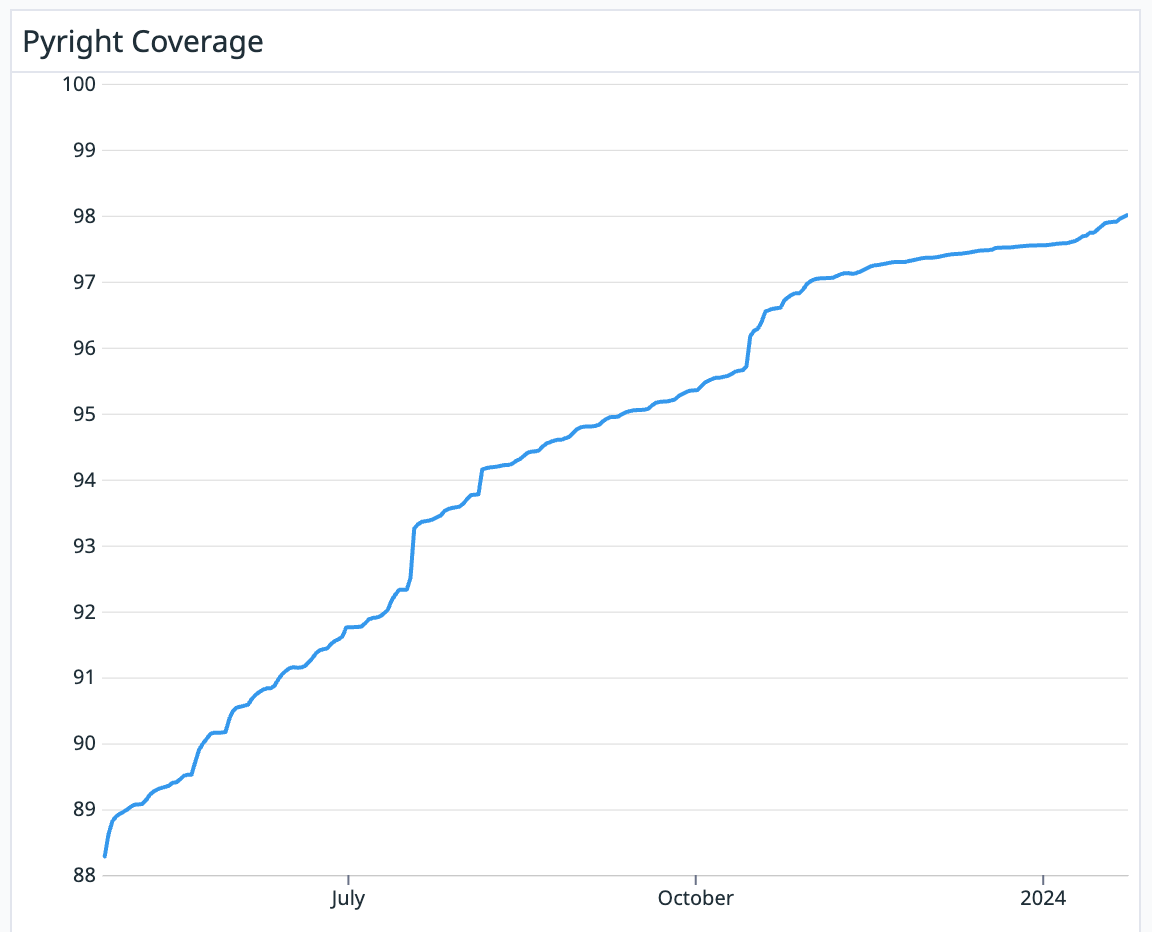
Our unfinished portrait
And after all that, here we are today. Two years ago we had no type coverage. Today over 98% of our codebase is covered by Pyright.
Are we done? Our director and 2024 OKRs would say that we are not. We would say we’ve quite a ways to go.
Alice Neel, I think, would say something different. Her painting is unfinished, and yet she signed it. It conveys everything it needs to: Here is this man whose expression and face are painted in immortal detail. The rest is unimportant. The traces of his essence convey all the feeling and depth we need to remember him in our everyday lives, even for something as banal as the leading metaphor into a blog post on Python type checking.
We’ll keep improving our code, of course. This isn’t the last you’ll hear about our work on code quality. But just to keep things in perspective, remember Alice Neel - even at 98%, you may find it inspiring to stop and celebrate your achievement.