


Ever wondered how B2B fintech companies handle finances as they grow and serve more customers? Let's find out by diving into Zip's recently launched accounting system!
TLDR
Zip’s accounting ledger service is a highly scalable, immutable, and eventually consistent system that underpins bookkeeping, reconciliation, and financial reporting for all payment transactions across all customers. The accounting ledger, which uses double-entry bookkeeping, serves as a source of truth for money movement activity and account balances within Zip, and also supports billing capabilities. Zip relies on Kafka (Amazon MSK) to ensure at-least-once delivery guarantee for its transactions.
A Tale of Tire Purchases
Let’s say Bike Company wants to buy tires worth $200 from one of its vendors, Acme Tire Company. Zip’s payment scheduling system sends a direct debit request to its payment provider. This pulls money from Bike Company's bank account and into their Zip wallet via direct debit. This money transfer is represented as a PAYIN_CREATED in the bookkeeping system.
Payment Provider Incoming Account
| Debit | Credit |
|---|---|
| $202.34 |
Bike Company’s Zip Wallet
| Debit | Credit |
|---|---|
| $202.34 |
The ledger entries represented above follow the double entry accounting pattern, where we have a debit entry to the Payment Provider Incoming Account and a credit entry to Bike Company's Zip Wallet.
Now, assuming the direct debit succeeded, the scheduling system will automatically pay $200 to Acme Tire Company and for that we issue a request to create a PAYOUT with object reference payout_bike_123.
Bike Company’s Zip Wallet
| Debit | Credit |
|---|---|
| $202.34 |
Payment Provider Outgoing Account
| Debit | Credit |
|---|---|
| $200.00 |
One might be wondering — what happens to the leftover $2.34 that was debited from Bike Company but never paid out to Acme Tire Company? $2.34 is the (illustrative) fee charged by Zip to cover its costs associated with the payment, which is reflected a little differently in the accounting system. As illustrated below, there is an additional credit entry to Payment Fee Accountwhich completes the payment lifecycle.
Payment Fee Account
| Debit | Credit |
|---|---|
| $2.34 |
Zip's Challenge
Zip has to keep track of money movement for hundreds of customers making thousands of transactions. Not only are there pay-ins and payouts as shown above, but we also have to process payout failures, foreign exchange payouts, internal billing events, and more! These events must be processed in a timely manner with 100% accuracy. The data produced will be used by our accounting and finance teams for both internal decision making and external reporting.
Fortunately, we've got some handy tools in our toolbox!
Tool No. 1: Event Processing
In our mission to build a robust accounting ledger system for Zip's financial operations, the role of an event streaming platform is crucial. Event streaming is a necessity for tackling the challenges we face in handling a growing number of financial transactions. Here's why it's essential and why we decided to go with streaming:
- Real-time Insight Needs: Getting near real-time insights into financial transactions is critical for making informed decisions, ensuring data accuracy, and meeting regulatory requirements. Event streaming allows us to capture, process, and act on financial events as they occur. This ensures our accounting ledger always reflects the most accurate and up-to-date financial data.
- Managing High Transaction Volumes: As Zip scales up, so does the sheer volume of financial transactions. Managing this high throughput efficiently poses an increasing challenge with traditional batch processing. Event streaming provides a practical way to handle a continuous flow of data.
In order for the accounting ledger to be successful, we knew we had to pick reliable streaming infrastructure, for which we decided to onboard Kafka.
Since Zip’s early days, Celery has been the only supported task streaming platform. Zip uses Celery to perform many fail-safe and non-critical tasks such as sending notifications and syncing transactions from our payment provider. However, Celery has its limitations — it doesn’t provide FIFO ordering guarantees, does not guarantee at-least-once-delivery, and cannot fan-out messages.
Kafka, designed for handling massive event streams, seemed like a well-suited alternative to manage Zip's ever-growing transaction volume. Data is replicated across multiple machines, and it guarantees at-least-once delivery. Kafka is also designed for horizontal scalability, allowing us to add more brokers, producers, and consumers to handle increased data loads. In addition to that, it supports producer / consumer decoupling, which makes it a good long-term choice if we ever decide to migrate to a micro-service architecture.
While deciding to use Kafka, we were aware that making a shift to a new event streaming platform involves a considerable amount of engineering cost. Onboarding a new streaming platform meant that we needed to set up brand new infrastructure to support Kafka across all environments, as well as provide observability and alerting functionality. However, now that we’ve started using Kafka in production and are seeing more and more use-cases of it within Zip, we are confident that we made the right choice to invest in Kafka.
Tool No. 2: Storage
Zip employs a graph-based database structure based on Facebook's Tao primarily consisting of two MySQL tables: object and association. To grasp how the data is organized, let's consider the example of a Vendor object. Vendor contains various fields like name, address, and country. All the data related to this Vendor is stored within a single column in the object table as a JSON blob. Consequently, we do not have access to out-of-the-box SQL features such as unique constraints, composite indexes, foreign keys, or idempotent CRUD operations.
Nevertheless, the accounting ledger system needs storage features such as atomicity, composite indexes, and unique constraints. For example:
- We cannot allow more than one
accounting_ledger_account_balanceobject for a singleaccounting_ledger_account. - We want to be able to swiftly retrieve all
accounting_ledger_entriesbyaccount_number, and therefore want to index theaccount_numberfield in theaccounting_ledger_entrytable.
Given these requirements and use cases, we made the decision to step away from our graph database and use vanilla MySQL.
Deep Dive
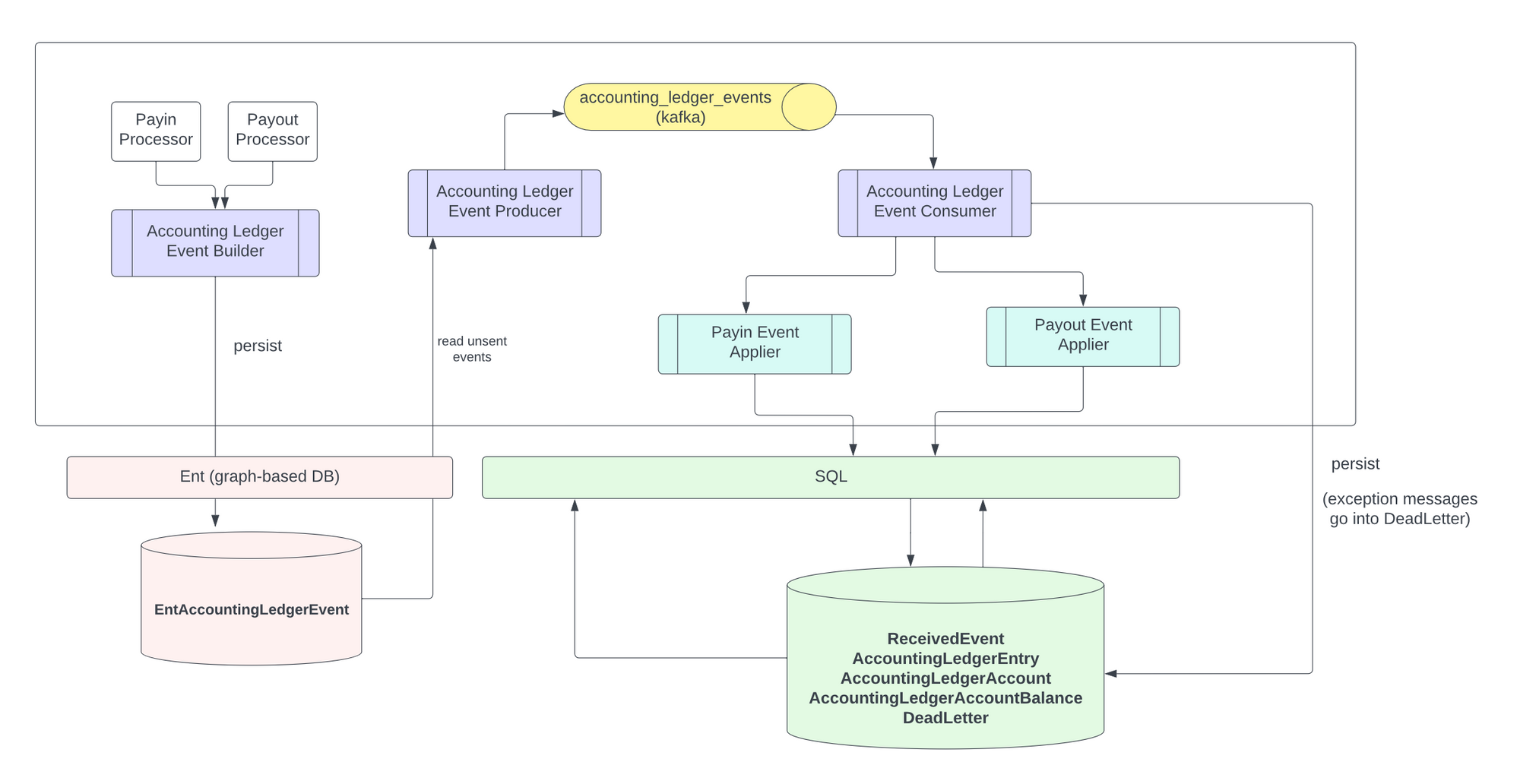
Now that we've covered our tools, let's dive into how they're applied in the life of an accounting event.
Creation: From Application Logic to Kafka
After Bike Company's payout payout_bike_123 to Acme Tire succeeds, Zip’s payments application code will create an accounting_ledger_event object, let’s say with id payout_creation_event_123. This event object is an application-side or “producer-side” event that is used as a point of reference throughout the lifecycle of event processing.
We use database constraints to ensure that this producer side event is unique based on an (object_id, scenario) tuple. For example, this ensures that we only account for the tuple (object_id=payout_bike_123, scenario=PAYOUT_CREATION) once!
In the same codepath, we enqueue a protobuf-serialized message in Kafka. This message contains all the necessary details for accounting purposes. If we ever store our accounting event object in our database, but fail to send it via Kafka, we have a background job which runs every periodically to pick up all unsent events and publish them to Kafka.
Event Processing: Logging our Debits and Credits
Our Kafka consumer will read a message and then execute accounting logic based on the event scenario, all within a database transaction. Scenarios include payout creation, payout failure, currency conversions, and several kinds of direct debit transactions.
As we stated previously, Kafka guarantees at-least-once delivery so we need to make sure that we deduplicate on the consumer side so our event-processing is idempotent. We do that with a second “consumer side” accounting event table. This table has a unique constraint based on the event id of the producer-side event.
So to understand that flow:
- A producer-side accounting event is created uniquely per
(object_id, scenario)with event idpayout_creation_event_123 - This producer event is enqueued in Kafka
- Our consumer picks up this event, and checks our consumer accounting event table to see if any event already exists for
producer_event_123. If there’s a unique violation, we skip processing the event. Otherwise, we account for our entries according to our scenario!
Death: Dead Letter Lifecycle
If anything goes wrong on the consumer side, we throw an exception that is caught outside of our transaction. Our transaction is then rolled back and a dead letter is created (or updated to “New” if one already exists for this event) in our dead letter queue. An on-call engineer will then be paged to look at our dead letter queue admin page and diagnose the situation.
After the issue is addressed, the engineer can re-enqueue the offending message to be retried. In this case, it will be republished to Kafka and reprocessed. Because the transaction failed to complete on the consumer-side, there will be no consumer-side events with the same producer-side event_id. Therefore, we should be good to re-process!
Measuring Success
Zip’s accounting ledger must be accurate, complete, and enable Zip to abide by financial regulations. From Kevin Chen, our controller -
"End of the day, we are aligned on what success looks like here, which is really accuracy (agreeing in total, variance at a transaction level both number of transactions and amount) and completeness; secondary metrics would be volume in number of customers and transactions."
From an engineering perspective, we can therefore define success as minimizing the amount of eng/ops/accounting hours necessary to meet our accuracy standards. This can easily be tracked via internal Asana task completion metrics. We should expect the engineer cost of month-end transaction reconciliation and reporting to drop from days to minutes!
Overall, it will be a clear sign of success if we can automate these processes such that producing accounting data is as easy as just zipping it!
Summary
We are rolling out the accounting ledger system to a select group of customers today. We are confident that this foundation will scale to support Zip’s accounting needs for all current and future customers for years to come. While the accounting ledger is a major step in Zip’s maturity as a payment provider, it is also the first internal reference implementation of Kafka at Zip, setting the example for a whole new world of asynchronous processing!